



╗∙ė┌öĄō■═┌Š“Ą─╣▄Ą└Ė▀║¾╣¹ģ^ųŪ─▄ūRäeĘų╬÷ŽĄĮy
üĒį┤Ż║ĪČ╣▄Ą└▒ŻūoĪĘļsųŠ ū„š▀Ż║ąż¹ÉŻ╗ÕXØ·╚╦Ż╗ĘČ╬─ĘÕŻ╗└Ņł@ ĢrķgŻ║2019-11-26 ķåūxŻ║
ąż¹É ÕXØ·╚╦ ĘČ╬─ĘÕ └Ņł@
šŃĮŁšŃ─▄╠ņ╚╗ÜŌ▀\ąąėąŽ▐╣½╦Š
š¬ ꬯║ļSų°╣▄ŠW║═│Ū╩ą╗»Ą─┐ņ╦┘░lš╣Ż¼╠ņ╚╗ÜŌ╣▄Ą└┤®įĮ╚╦┐┌├▄╝»ģ^Ą─Ūķør╚šęµ═╗│÷Ż¼čžŠĆĖ„╝ēš■Ė«ę¬Ū¾╣▄Ą└Ų¾śI╚½├µķ_š╣╚╦åT├▄╝»ą═Ė▀║¾╣¹ģ^ūRäe║═’LļUįuār╣żū„ĪŻé„ĮyĄ─╚╦╣żūRäeĘĮĘ©┤µį┌öĄō■▓╔╝»└¦ļyĪó£╩┤_Č╚▓╗Ė▀Īóą¦┬╩Ą═Ą╚╚▒³cŻ¼¤oĘ©ØMūŃŲ¾śIīŹļHąĶŪ¾ĪŻšŃĮŁšŃ─▄╠ņ╚╗ÜŌ▀\ąąėąŽ▐╣½╦Š│õĘų└¹ė├¼FėąĄ─▀bĖąė░Ž±Ż©DOMŻ®║═ŠĆäØłDŻ©DLGŻ®Ż¼▓╔ė├öĄō■═┌Š“ĘĮĘ©īŹ¼F┴╦Ė▀║¾╣¹ģ^Ą─ėąą¦ūRäeĪŻ
ĻPµIį~Ż║Ė▀║¾╣¹ģ^ūRäeŻ╗Į©ų■öĄō■╩Ė┴┐╗»Ż╗ DBSCANŠ█ŅÉ╦ŃĘ©
šŃĮŁ╩ĪĮøØ·░l▀_Ż¼═┴Ąž┘Yį┤ŠoÅłŻ¼╠ņ╚╗ÜŌ╣▄Ą└ų▄ć·╚╦┐┌├▄╝»Ż¼ą╬│╔┴╦┤¾┴┐Ė▀║¾╣¹ģ^Ż¼ę╗Ą®░l╔·ą╣┬®▒¼š©╩┬╣╩Ż¼īóĢ■Įo╚╦├±╔·├³║═žö«aĦüĒŠ▐┤¾ōp╩¦ĪŻ
▌öÜŌ╣▄Ą└Ė▀║¾╣¹ģ^Ęų╝ēĄ─Ū░╠ß╩ŪĮyėŗ╣▄Ą└ųąą─ŠĆā╔é╚ų┴╔┘200├ūĘČć·ā╚Ą─╦∙ėąĮ©ų■öĄō■Ż¼é„Įy╚╦╣ż¼Fł÷ūRäeĘĮĘ©ūRäeĢrķgķLĪó│╔▒ŠĖ▀Īó┘|┴┐Ą═Ż¼║─┘M┤¾┴┐╚╦┴”Īó╬’┴”Īóžö┴”Ż¼ęč¤oĘ©┼cŲ¾śI╠ß┘|į÷ą¦Ą──┐ś╦ŽÓ▀mæ¬Ż¼╚ń║╬£╩┤_Ė▀ą¦ūRäe╣▄Ą└Ė▀║¾╣¹ģ^│╔×ķ▒žĒÜ╦╝┐╝┼cĮŌøQĄ─å¢Ņ}ĪŻ
╗∙ė┌öĄō■═┌Š“Ą─╠ņ╚╗ÜŌ╣▄Ą└Ė▀║¾╣¹ģ^ūRäeŽĄĮyŻ©ęįŽ┬║åĘQūRäeŽĄĮyŻ®ę└═ąė┌ųŪ╗█ė═ÜŌ╣▄ŠWĮ©įOŻ¼═©▀^īó╠ņ╚╗ÜŌ╣▄Ą└┼c┤¾öĄō■Ęų╬÷ŽÓĮY║ŽŻ¼▓╔╚ĪĮ©ų■öĄō■╩Ė┴┐╗»Ą─äōą┬ĘĮ╩Į▀MąąöĄō■▓╔╝»Ż¼╗∙ė┌├▄Č╚Ą─DBSCANŠ█ŅÉ╦ŃĘ©Ė▀ą¦ųŪ─▄£╩┤_Ąž═Ļ│╔Ė▀║¾╣¹ģ^ūRäe╣żū„Ż¼īŹ¼F╠ņ╚╗ÜŌ╣▄Ą└╣▄└Ēą┼Žó╗»ĪóöĄūų╗»Ż¼╚ĪĄ├┴╦║▄║├Ą─ą¦╣¹ĪŻ
1 öĄō■▓╔╝»
1.1 öĄō■Äņ┤ŅĮ©
öĄō■Äņęįķ_į┤PostgreSQLöĄō■Äņ×ķ║╦ą─Ż¼═©▀^öUš╣PostGISĮM╝■Ż¼Į©┴óPostgreSQLöĄō■ÄņĄĮArcGIS═©Ą└Ż¼īŹ¼F┐šķgĄž└ĒöĄō■┤µā”┼c╣▄└ĒŻ╗═©▀^öUš╣TimescaleDBĮM╝■Ż¼Į©┴óPostgreSQLöĄō■ÄņĻP┬ōŻ¼īŹ¼FĢrķgą“┴ąöĄō■┤µā”║═╣▄└ĒŻ╗═©▀^öUš╣MinIOĮM╝■Ż¼Į©┴óī”Ž¾öĄō■┼cPostgreSQLöĄō■ÄņĄ─ĻP┬ōŻ¼īŹ¼FššŲ¼Īó╬─ÖnĄ╚öĄō■┤µā”┼c╣▄└ĒĪŻÅ─Č°īŹ¼F┴╦ę╗īŻČÓ─▄Ą─Ģr┐š╚½ŚŻöĄō■ÄņŻ¼ØMūŃöĄō■═┌Š“╦∙ąĶĄ─Ė„ĘNŅÉą═öĄō■┤µā”║═Öz╦„╚½Žóą┼ŽóĪŻ
1.2 öĄō■Ęųīė
ūRäeŽĄĮy╦∙ę└┘ćĄ─Ą┌ę╗īėŻ©ūŅĄūīėŻ®öĄō■╩Ūš²╔õ▀bĖąė░Ž±Ż©DOMŻ®Ż¼įōöĄō■üĒį┤ė┌ūŅą┬ąląŪ▀bĖą║═║Į£yė░Ž±öĄō■Ż¼ų▒ė^Ę┤ė│┴╦╣▄Ą└ų▄▀ģĄ─ŁhŠ│Ż¼Ą½ŲõāH×ķė░Ž±öĄō■Ż¼¤oĘ©ų▒Įėė├ė┌Ė▀║¾╣¹ģ^Ą─ūRäeĪŻĄ┌Č■īėöĄō■×ķöĄūųŠĆäØłDŻ©DLGŻ®Ż¼īóė░Ž±öĄō■ųąĄ─Į©ų■ ▐DōQ×ķ╩Ė┴┐Ż¼īóĮ©ų■ś╦ėø║¾ū„×ķę╗éĆČÓ▀ģą╬▒Ż┤µį┌┐šķgöĄō■Äņ└’ĪŻĄ┌╚²īėöĄō■×ķĮ©ų■ī┘ąįöĄō■Ż¼╚ńĮ©ų■ŅÉą═Īó┬ōŽĄ╚╦╝░ļŖįÆĄ╚ĪŻ
1.3 öĄō■╠Ä└Ē
╩ūŽ╚═©▀^Üw╝{Ęų╬÷Ż¼ī”┐šķgöĄō■ÄņĄ─öĄō■ŅA╠Ä└ĒĪŻ
Ż©1Ż®ßśī”╣▄Ą└ų▄ć·┤¾┴┐▐r┤ÕūĪš¼Ż¼ŲõŠĆäØłDķLīÆ▒╚ėąę╗Č©Ą─ĘČć·Ż¼Ė▀Č╚ę╗░Ń▓╗│¼▀^4īėŻ¼└¹ė├╝ż╣Ō└ū▀_³cįŲöĄō■½@Ą├Ą─Į©ų■╬’ĒöīėĖ▀Č╚Ż¼Š═┐╔ęįīó▐r┤ÕūĪš¼ĘųŅÉŻ¼▐r┤ÕūĪš¼Č©┴x×ķę╗┤▒ę╗æ¶ĪŻ
Ż©2Ż®ąĪģ^ūĪš¼Ż¼Üw╝{ąĪģ^ūĪš¼Ą─ķLīÆ▒╚Ż¼┐╝æ]ŠĆäØłDĄ─├µĘe║═ūĪš¼ąĪģ^├┐æ¶├µĘeį┌70Ī½130ŲĮĘĮ├ūŻ¼Į©┴óöĄīW─Żą═┐╔═Ųī¦├┐īėæ¶öĄĪŻąĪģ^ūĪš¼ę╗░ŃĖ▀Č╚Š∙│¼▀^7īėŻ¼└¹ė├ŠĆäØłDĖ▀Č╚ī┘ąįŻ¼┐╔═Ųī¦│÷īėöĄŻ¼ė╔┤╦┐╔ėŗ╦Ń│÷ę╗┤▒ūĪš¼Ą─ūĪæ¶öĄĪŻ
Ż©3Ż®╣żÅSĪó╔╠ł÷Ą╚╠žČ©ł÷╦∙║═ūĪš¼ą╬ĀŅĪóķLīÆ▒╚ĪóĖ▀Č╚Š∙ėą▓Ņ«ÉŻ¼═©▀^ėŗ╦ŃŻ¼īó╣żÅS╔╠ł÷Ą╚╠žČ©ł÷╦∙ĘųŅÉś╦ūóĪŻ
Ż©4Ż®ė╔ė┌ŠĆäØłDŠ∙ėąŠ½┤_Ą─GPSū°ś╦Ż¼═©▀^┼c░┘Č╚Īó BIGMAPĄ╚ĄžłDöĄō■Ą─╬╗ų├Ųź┼õŻ¼─▄ē“╚ĪĄ├╠žČ©ł÷╦∙Ą─ī┘ąįŻ¼╚ńå╬╬╗├¹ĘQĪó┬ōŽĄ╚╦╝░ļŖįÆĪóįö╝ÜĄžųĘĄ╚ą┼ŽóĪŻĮ©ų■ś╦ūóŠG╔½×ķ▐r├±ūĪš¼Ż¼╦{╔½×ķąĪģ^ūĪš¼Ż¼³S╔½×ķę╗░Ń╠žČ©ł÷╦∙Ż¼╝t╔½×ķęū╚╝ęū▒¼ł÷╦∙ĪŻ
1.4 öĄō■═Ļ╔Ų
ßśī”PCČ╦¤oĘ©┤_šJĄ─▓┐ĘųĮ©ų■öĄō■Ż¼└¹ė├╩ųÖCČ╦Ė▀║¾╣¹ģ^▓╔╝»APP║╦īŹ¼Fł÷öĄō■Ż¼┐╔ų▒Įėī¦║Įų┴įōĮ©ų■╬╗ų├Ż¼┤¾┤¾╣Ø╩Ī┴╦¼Fł÷öĄō■▓╔╝»ĢrķgĪŻ
ī”┤µā”į┌öĄō■ÄņųąĄ─╣▄Ą└ā╔é╚200├ūĄ─╦∙ėąĮ©ų■öĄō■ūįäėŅA╠Ä└Ē▓ó¼Fł÷║╦īŹ═Ļ╔Ų║¾Ż¼▓╗āH┐╔┐ņ╦┘┤_Č©Ė„ŅÉūĪš¼╦∙░³║¼Ą─æ¶öĄŻ¼Č°Ūęī”╠žČ©ł÷╦∙▀Mąąś╦ūóĪŻĮ©ų■öĄō■Ą─╩Ė┴┐╗»×ķĖ▀║¾╣¹ģ^ųŪ─▄ūRäeĘų╬÷┤“║├╗∙ĄAŻ©łD 1Ż®ĪŻ
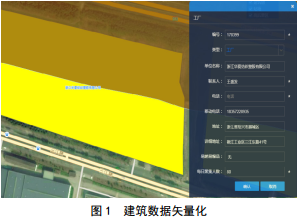
2 ųŪ─▄ūRäe
2.1 ūRäe£╩ät┴┐╗»
ę└ō■GB 32167©D2015ĪČė═ÜŌ▌ö╦═╣▄Ą└═Ļš¹ąį╣▄└ĒęÄĘČĪĘŻ¼ĮY║Ž╣½╦Š╣▄Ą└ų▄▀ģĮ©ų■īŹļHĘų▓╝ŪķørŻ¼╣½╦Š┴┐╗»┴╦╣▄Ą└Ė▀║¾╣¹ģ^ūRäe£╩ätĪŻ
Ż©1Ż®ó¾╝ēĖ▀║¾╣¹ģ^Ż║╦─╝ēĄžģ^Ż¼─│Ąžģ^▀B└m│÷¼F10┤▒4īė╝░ęį╔ŽĮ©ų■Ż©▓╗░³└©▐r┤ÕūĪš¼Ż¼ę╗░ŃųĖąĪģ^ūĪš¼Ż®ĪŻ
Ż©2Ż®ó“╝ēĖ▀║¾╣¹ģ^Ęų×ķęįŽ┬╚²ĘNŪķørŻ║
ó┘╚²╝ēĄžģ^Ż¼æ¶öĄ100æ¶ęį╔ŽĪŻ
ó┌▀B└mėą10éĆ╣żÅSŻ¼ā╔éĆ╣żÅSų«ķgķgĖ¶▓╗│¼▀^30├ūĪŻ
ó█Ųõ╦¹┤µį┌ęū╚╝ęū▒¼ł÷╦∙Ą─Ąžģ^ĪŻ
Ż©3Ż®ó±╝ēĖ▀║¾╣¹ģ^Ż║Ųõ╦¹┤µį┌╠žČ©ł÷╦∙Ą─Ąžģ^,╚ńīWąŻĪóėūā║ł@Īóßtį║Ą╚ĪŻ
2.2 ║╦ą─╦ŃĘ©
2.2.1 ╦ŃĘ©įŁ└Ē
═Ļ│╔öĄō■ŅA╠Ä└Ē║¾Ż¼▀@ą®Į©ų■┐╔ęį┐┤│╔╩Ūę╗éĆĦėąæ¶öĄī┘ąįĄ─³cĪŻ▀@ą®³cį┌╣▄Ą└ų▄ć·Ą─Ęų▓╝ø]ėą╠žČ©ą╬ĀŅŻ¼ą╬│╔ę╗Č©Ą─╔ó▓╝Ż¼čž╣▄ŠĆėŗ╦Ń┤_Č©Į©ų■Ż©æ¶öĄŻ®├▄╝»ģ^ė“╝┤┐╔īŹ¼FĖ▀║¾╣¹ģ^Ęų╝ēĪŻ
│Żė├Ą─Š█ŅÉ╦ŃĘ©ėąk-means╦ŃĘ©Ż¼įćė├║¾░l¼Fk-means╦ŃĘ©╗∙ė┌ŲĮŠ∙ŠÓļxøQČ©═¼ŅÉŠ█╝»Ż¼▀mė├ė┌Ū“ą╬Š█╝»Ż¼▓╗▀m║Ž├±Ę┐┐šķgĘų▓╝ĪŻ═©▀^▒╚▌^蹊┐Ż¼▀xō±┴╦Š▀ėąįļ┬ĢĄ─╗∙ė┌├▄Č╚Ą─DBSCANŻ©Density-BasedSpatial Clustering of Applications with Noise)Š█ŅÉ╦ŃĘ©Ż¼įō╦ŃĘ©╩Ūęį├▄Č╚ĪóČ°▓╗╩ŪŠÓļxüĒėŗ╦Ń┤ž║═┤ž▀ģĮńĪŻŲõ╗∙▒Š╦╝┬ĘŻ©łD 2Ż®╩ŪęįĮ©ų■├▄╝»ģ^ė“Ą──│ę╗Į©ų■×ķłAą─Ż¼▀xō±║Ž▀m░ļÅĮ«ŗłAŻ¼╝┤ęÄČ©┴╦łAĄ─░ļÅĮ╝░łAā╚ūŅ╔┘░³║¼Ą─Į©ų■├▄Č╚ĪŻ╚¶łAā╚Į©ų■├▄Č╚┤¾ė┌Ą╚ė┌ŅAŽ╚ųĖČ©Ą─ųĄŻ¼─Ū├┤▀@éĆłA╚”Ą─łAą─Š═▐DęŲų┴įōłA╚”ā╚Ą─Ųõ╦¹Į©ų■Ż¼└^└m«ŗłA╚źėŗ╦ŃŻ¼ų▒ų┴łAā╚╦∙░³║¼Ą─Į©ų■├▄Č╚╔┘ė┌ŅAŽ╚ųĖČ©Ą─ųĄŻ¼Š█ŅÉĮKų╣ĪŻ╗∙ė┌├▄Č╚Ą─DBSCANŠ█ŅÉ╦ŃĘ©▀mė├ė┌į┌╣▄ŠĆų▄ć·Į©ų■Ęų▓╝ģ^ė“ųąŻ¼╚źīżšęĖ▀├▄Č╚Ęų▓╝Ą─ģ^ė“Ż¼▓ó┼cĮ©ų■Ęų▓╝ą╬ĀŅ¤oĻPĪŻ
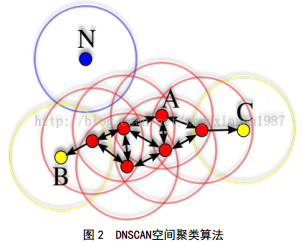
2.2.2 ╦ŃĘ©æ¬ė├
Ė∙ō■┴┐╗»║¾Ą─╣▄Ą└Ė▀║¾╣¹ģ^ūRäe£╩ätŻ¼īó╗∙ė┌├▄Č╚Ą─DBSCANŠ█ŅÉ╦ŃĘ©æ¬ė├ĄĮĖ▀║¾╣¹ģ^ūRäeųąĪŻęį╣▄ŠĆ×ķ╗∙▒Šå╬╬╗Ż¼╩ūŽ╚š{ė├┐šķgöĄō■ÄņųąĄ─ąĪģ^ūĪš¼Ż¼ ░ļÅĮįOų├│╔100├ūŻ¼öĄ┴┐įOų├×ķ10Ż¼ėŗ╦Ń│÷ąĪģ^ūĪš¼┤žĄ─ģ^ė“Ż¼ØMūŃūRäeś╦£╩Ģrīóįōģ^ė“äØĘų×ķó¾╝ēĖ▀║¾╣¹ģ^ĪŻ
╚ź│²ąĪģ^ūĪš¼┤ž║¾Ż¼š{ė├┐šķgöĄō■Äņųąś╦ėą╣żÅSĪó╔╠śIĮ©ų■Ą╚Į©ų■Ż¼░ļÅĮįOų├│╔100├ūŻ¼öĄ┴┐įOų├×ķ10Ż¼ėŗ╦Ń│÷╣żÅSĪó╔╠śIĮ©ų■┤žĄ─ģ^ė“Ż¼ØMūŃūRäeś╦£╩Ģrīóįōģ^ė“äØĘų×ķó“╝ēĖ▀║¾╣¹ģ^ĪŻ
╚ź│²ęį╔Žā╔éĆ┤ž║¾Ż¼š{ė├┐šķgöĄō■Äņųąś╦ėą▐r┤ÕūĪš¼Ą─Į©ų■Ż¼░ļÅĮįOų├×ķ50├ūŻ¼öĄ┴┐×ķ100Ż¼ėŗ╦Ń│÷├±Šė┤žĄ─ģ^ė“Ż¼ØMūŃūRäeś╦£╩Ģrīóįōģ^ė“äØĘų×ķó“╝ēĖ▀║¾╣¹ģ^ĪŻ
╚ź│²ęį╔Ž╚²éĆ┤ž║¾Ż¼Ė∙ō■öĄō■ŅA╠Ä└Ē║¾╠žČ©ł÷╦∙ś╦ūóĄ─ī┘ąįŻ¼ęū╚╝ęū▒¼ł÷╦∙äØ×ķó“╝ēĖ▀║¾╣¹ģ^Ż¼Ųõ╦¹ł÷╦∙äØ×ķó±╝ēĖ▀║¾╣¹ģ^ĪŻ
3 ūįäėĮyėŗĘų╬÷
ūRäeŽĄĮyī”1 766╣½└’Ż©ĮøĮyėŗ╣▄Ą└ų▄▀ģĮ©ų■8╚fČÓéĆŻ®╠ņ╚╗ÜŌ╣▄ŠW▀Mąą┴╦Ė▀║¾╣¹ģ^ūįäėūRäeĪŻ╗∙ė┌Å═║ŽłD╬─ę╗¾w╗»ųŪ─▄ł¾Ėµ╔·│╔╝╝ągŻ¼░┤ł¾Ėµ─Ż░ÕūįäėĮyėŗĘų╬÷öĄō■▓óęįłD▒ĒĖ±╩Įš╣╩ŠŻ©łD 3Ż®Ż¼ 1ąĪĢrā╚╝┤┐╔│÷Š▀╚½╩Ī╣▓55Ę▌ł¾ĖµĪŻ
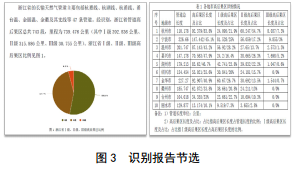
4 ╣”─▄īŹ¼F
╗∙ė┌öĄō■═┌Š“Ą─╣▄Ą└Ė▀║¾╣¹ģ^ųŪ─▄ūRäeŽĄĮyĄ─ķ_░læ¬ė├│╔╣”Ż¼ę╗╩ŪīŹ¼F┴╦╣▄Ą└Ė▀║¾╣¹ģ^Ą─Š½£╩ūRäeŻ¼▀_ĄĮ╣▄Ą└Ė▀║¾╣¹ģ^Ą─öĄō■╗»Īó┐╔ęĢ╗»╣▄└Ē─┐ś╦Ż¼×ķš■Ė«╝░╣▄Ą└Ų¾śI╣▄└Ē╠ß╣®ėą┴”ę└ō■ĪŻČ■╩Ūėąą¦ĮĄ▒Š╠ß┘|į÷ą¦Ż¼ØMūŃŲ¾śIįĮüĒįĮĖ▀Ą─Š½╝Ü╗»╝░ĮøĀI╣▄└ĒĄ─ę¬Ū¾ĪŻ╚²╩Ū┐╔┼cŲõ╦¹╣▄Ą└▒ŻūośI䚎ĄĮyĻP┬ōŻ©╚ń┼cæ¬╝▒╣▄└ĒŽĄĮyĻP┬ōŻ®Ż¼īŹ¼FöĄō■╣▓ŽĒŻ¼▀Mę╗▓Į╝ėÅŖ╣▄Ą└░▓╚½▀\ąą╣▄└ĒĪŻ╦─╩ŪīŹ¼F┴╦╗∙ė┌╣▄Ą└Ė▀║¾╣¹ģ^Ą─┤¾öĄō■╣▄└Ē┼cŠSūoŻ¼Å─öĄō■▓╔╝»ĪóöĄō■š╣╩ŠĪóöĄō■æ¬ė├ĄĮöĄō■Ė³ą┬Ż¼īŹ¼FöĄō■Ą─Ė▀ą¦▓╔╝»Īóų▒ė^š╣╩ŠĪóĮyėŗĘų╬÷╝░Ė³ą┬Ą─╚½▀^│╠╣▄└ĒŻ¼į÷ÅŖöĄō■Ą─īŹė├ąįŻ©łD 4Ż®ĪŻ
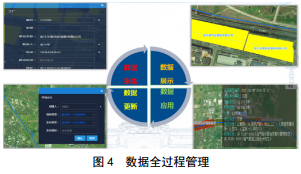
5 ĮYšō
╣▄Ą└Ė▀║¾╣¹ģ^ųŪ─▄ūRäeŽĄĮyūRäe┘|┴┐Ė▀Ż¼Ė▀║¾╣¹ģ^Ą╚╝ēäØĘųŠ∙ėąöĄō■┐╔ūĘ╦▌Ż¼▓óėąČÓĘNĮyėŗŠSČ╚Ż¼╚ń░┤šš╚½╩ĪĖ„Ąž╩ąąąš■ģ^äØĮyėŗĪó╣½╦Š╣▄Ą└╣▄└Ēå╬į¬ĮyėŗĪóūRäeĢrķgĮyėŗĪóĖ▀║¾╣¹ģ^╝░Ųõūā╗»ŪķørĮyėŗĄ╚Ż¼╚ĪĄ├┴╦╩ų╣żūRäe¤oĘ©ū÷ĄĮĄ─ūRäeĮY╣¹Ż¼ĄņČ©┴╦╣▄Ą└═Ļš¹ąį╣▄└Ē╗∙ĄAŻ¼ę▓║╗īŹ┴╦æ¬╝▒ŅA░Ė┬õĄž╗∙³cŻ¼īóėąą¦╠ßĖ▀╣▄Ą└’LļUŽ¹£pą¦╣¹ĪŻ
ū„š▀Ż║ąż¹ÉŻ¼┼«Ż¼ 1992─Ļ╔·Ż¼ų·└Ē╣ż│╠ĤŻ¼ 2015─Ļ«ģśIė┌ųąć°╩»ė═┤¾īWŻ©╚A¢|Ż®ė═ÜŌā”▀\īŻśIŻ¼¼Fų„ę¬Å─╩┬╣▄Ą└▒Żūo╣żū„ĪŻÕXØ·╚╦Ż¼ 1963─Ļ╔·Ż¼Ė▀╝ē╣ż│╠ĤŻ¼┐Ųäōųąą─ų„╚╬Ż¼¼Fų„ę¬Å─╩┬╣▄Ą└Ž╚▀M┐Ų╝╝╝╝ąg蹊┐╣żū„ĪŻ
╔ŽŲ¬Ż║
Ž┬Ų¬Ż║
 Ė╩╣½ŠW░▓éõ 62010202003034╠¢
Ė╩╣½ŠW░▓éõ 62010202003034╠¢ 
